|
Description
The project builds a web service for a BioInformatics tool 'Phrap'. The web service has been built using WebSphere. The project was aimed at understanding the implementation issues of web service development. Client and server exchange SOAP messages. Web service is registered to a private UDDI registry. This service can be fetched by querying the UDDI registry from a web Browser. Service provides a WSDL document to generate the client stub.
Phrap takes a long time for executing on a large chicken EST file. The aim was to coordinate this task among several parallel instances of the web service, running on different processors
Abstract:
Web Services are self contained modular applications that have open, internet-oriented, standard based interfaces. In addition to being able to locate and utilize them within your own applications, you can also create and publish them to meet the business goals.
Web Services promote loose coupling distributed services that collaboratively provide business processes. The Web Service architecture is built on a number of protocols all of which together provide a robust implementation.
These include:
- HTTP – The de facto standard for the internet
- XML – The de facto standard for data message interpretation
- SOAP – Chosen standard for XML messaging
- WSDL - Standard for interface definition
- UDDI – The Web Service registry
The project aimed at gaining a better understanding of the Web Service architecture by implementing a Web Service. I used Web Sphere studio and Web Sphere application server for Web Service development and deployment.
Phrap utility is an important tool in the field of Bioinformatics which takes as input a file containing EST sequences, and produces a file containing contigs. This utility takes a long time for large input files.
The project’s objective was to design and implement a Web Service architecture that can reduce this execution time by coordinating among parallel instances of Phrap service running on different processors on the cluster.
I designed and implemented the Phrap Web Service in a reduced magnitude and tested it on a chicken EST file containing 400,000 EST’. The architecture has been designed to easily scale to a larger infrastructure.
Why a Web Service Implementation?
Web Services provide following benefits:
Interoperability: Heterogeneous environments from various development environments (J2EE, CORBA, .Net) can be integrated into business applications.
Reuse: Developers can locate an existing web service provided by third parties and incorporate these into their solution.
Ubiquitous: Web Services make applications developed in various platforms visible. In future Web service tools will be available on most development platforms to make it easier to extend applications to Web Services.
Business flexibility: Developers can customize the existing services by wrapping them as per customer needs.
Easy application integration: As web services proliferate, independent software vendors can develop software packages that expose the services based on the Web services standard. These services can be easily integrated as compared to conventional enterprise application integration problems with differing information interfaces.
Components of Web services

Web services are deployed on the web by services providers. The functions provided by the Web service are described using WSDL. The service providers publish deployed services on the Web through brokers.
A service broker helps the service providers and service requestors locate each other. A service requestor uses the UDDI API to ask the service broker about the services it needs. When the service broker returns the search results, the service requestor can use those results to bind to a particular service.
The development cycle takes you through one or all of these steps:
- Discovery: Find a service and support the necessary interface.
- Create or transform: You either create your own service or transform your application to comply with a discovered interface.
- Build: The build phase of the lifecycle includes development and testing of the Web service implementation, the definition of the service interface description, and the definition of the service implementation description. Web Service implementation can be provided by creating new Web services, transforming existing applications into Web services, and composing new Web services from other Web services and applications.
- Deploy: The deploy phase includes the publishing of the service interface and service implementation definition to a service requestor or service registry.
- Test: A UDDI registry can be used to publish and test the service. A private UDDI registry can be used for testing.
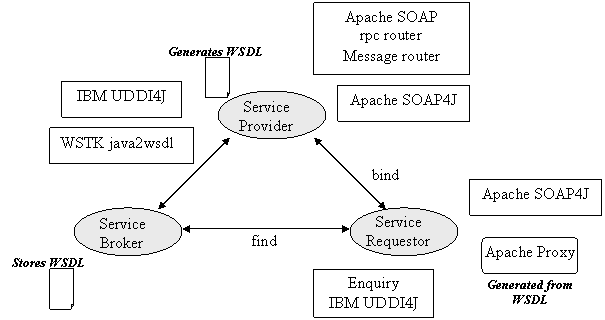
WebSphere supports WSDL 1.2, Apache SOAP 2.3 and UDDI 2.0. WebSphere comes with Web services Tool Kit (WSTK) from IBM Alpha Works. The tools that come with WebSphere and the WSTK provide various functionalities for creating web services. Some of these tools are listed as follows:
UDDI4J: IBM’s Universal Description, Discovery Integration open-source implementation for Java development of UDDI which provides capability to interface UDDI registry. This enables WebSphere applications to communicate with UDDI compliant registries to publish and locate Web services.
WSDL4J: IBM’s Web Services Description Language open source implementation for Java development of WSDL which provides the way to describe Web services’ location and invocation.
Apache SOAP4J: Apache SOAP 2.3 is supported in WebSphere to provide a SOAP server and client application environment. This support gives WebSphere applications capability to send and receive SOAP messages.
Apache SOAP handles two types of requests: message based and rpc based. It processes SOAP requests through rpc router and message router.
WebSphere also enables creation of services from Java classes, EJBs etc through pluggable providers which are described with SOAP deployment descriptors.
The Phrap’ing of a file consisting of large number of ESTs (fasta sequences) takes a long time for execution. One of the evidences of this fact is the chicken EST file that we are dealing with, which takes around 20 days for Phrap’ing.
Hence the proposed architecture is based primarily on reducing this execution time by the following strategy:
- Since the input file is large, split the input file into smaller parts and Phrap each of them parallel.
- This will reduce the number of contigs in each part. If the number of contigs has reduced substantially append the contigs of two parts and run Phrap again.
- The above step continues till we obtain a single file which contains the same number of contigs even after Phrap’ing.
The reasons for the performance gain by the above strategy are:
- We can exploit the available processors on the cluster to run parallel instances of Phrap, which reduces the execution time by large amount.
- By using this Divide and Conquer approach, we in turn reduce the number of contigs. This speeds up the final Phrap execution of the integrated file.
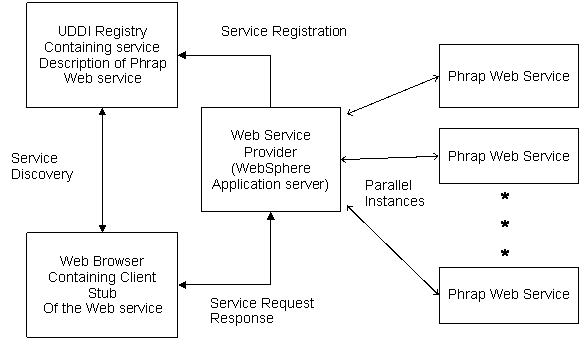
The Phrap Web Service provider registers with UDDI registry and a WSDL document. The Phrap service requestor discovers this service and creates a client stub from this WSDL file. The service asks for a input EST file and returns a Phrap’ed file.
The service provider implements the above strategy by using multiple Pharp services executing on multiple processors on the cluster. The service provider acts as a coordinator among these parallel running processes. The user is unaware of the underlying architecture.
Number of contigs in the Input file
The Phrap execution time and the reduction in number of contigs largely depends on the number of input contigs. If the number of contigs in the file is too small, then even after running Phrap on the file, it does not decrease significantly. On the other hand, if the number of contigs is too large, then executing Phrap on the file takes a long time. Hence an we need an optimal number of contigs in the input file. We tested the execution time for performing the Phrap service for different number of contigs in the file. The observations are as follows:
No. of input ESTs (contigs) |
No. of output contigs |
Execution time (min) |
2,000 |
1,441 |
1.5 |
5,000 |
3,277 |
3.25 |
10,000 |
5,076 |
15 |
20,000 |
9,405 |
~50 |
50,000 |
… |
150 |
From the above runs, it can be clearly seen that a running Phrap on a file containing 20,000 ESTs for the first run is best.
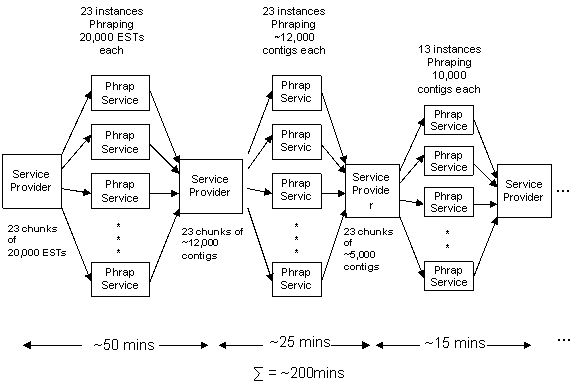
The client requesting the Phrap Web Service sends as input a large file containing ESTs. The service provider receives the file and then during the first run splits the file into 23 chunks of 20,000 ESTs each. Each of the 23 instances of Phrap service are inputted one of the above 23 chunks. The service instances perform Phrap on the input and return an appended contig file and a singlet file to the service provider. This results in 23 chunks of approximately 12,000 contigs each. The instances of Phrap service are assigned as input, one the above 23 chunks. The service instances Phrap the inputted file and returns the appended contig-singlet output to the service provider. The service provider again appends the output from each one of the 23 instances to create a new file as explained above. The service provider then splits the newly created file into 13 chunks of ~10,000 FASTA sequences (contigs + singlets) .The chunks are then inputted to the 13 Phrap service instances. Again, the instances perform Phrap on the input and return the output. The above process is repeated, each time decreasing the number of chunks in which the file is split, till we obtain a single file containing about 30,000 contigs, which even on Phrap’ing remains the same or contains the same number of contigs.
If the service provider implements the Phrap service in the above mentioned way, then we estimated that the total time to Phrap the entire file (for the given chicken EST file) would be about 6 hrs , in the worst case.
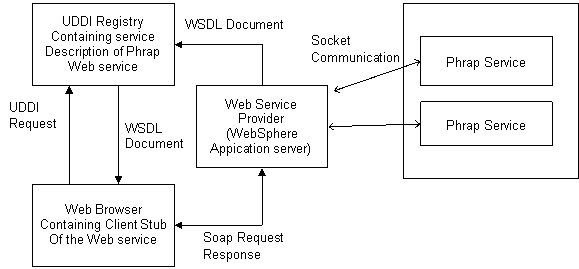
We are using Windows based WebSphere Studio and WebSphere Application Server to develop the Phrap Web Service. The WebSphere application server resides on a Windows machine, generates a WSDL document and registers to a private UDDI registry. The client can access this service through a web browser after a UDDI discovery process.
The service provider receives the input file and coordinates the proposed strategy in a reduced magnitude among two phrap services running on Strauss. The implementation is scalable to any number of phrap service instances and hence can be deployed on multiple processors as proposed.
1) I could substantially reduce the time required to phrap a chicken EST file, by parallel execution of multiple instances of phrap Web Service as mentioned above
2) Web Service interface provides an easy, interoperable and reusable application
3) User is unaware of the underlying complexity of the architecture involved. The User just inputs a file to the Phrap service provider and the service provider performs the task as mentioned above and returns the final output file to the user.
- WebSphere Bible – B. Kataoka, D.Ramirez, A.sit
- www.ibm.com
- WebSphere studio online documentation
- Phrap documentation
|


