2.1.4. Datos Agrupados: se llaman así porque al depender de tantos valores, analizarlos de manera individual resulta tedioso, pro además el verdadero valor de la información se pierde sí estos no se agrupan.
Edades de una Población de 60 personas.
20 18 20 30 10 8 11 13 19 15 18 21
22 30 25 10 9 14 15 16 20 10 12 16
20 15 17 17 30 29 28 16 10 13 17 30
9 18 16 20 23 11 15 21 23 25 30 10
15 17 30 10 11 12 19 22 21 10 13 14
Si se observan estos datos, es notable la necesidad del agrupamiento, pues resultan ser demasiados valores para analizarlos de manera simple. La forma y la importancia de los datos agrupados, serán tratadas en el desarrollo de otros temas más adelante.
2.2. El Cuadro o Tabla Estadística
Cuando los datos se agrupan en clases y frecuencias lo más conveniente es usar cuadro o tabla estadística. Este recoge un cúmulo de informaciones o datos donde debe haber (3) elementos importantes como son:
Ejemplo: Edades de una muestra de 100 estudiantes que ingresaron a AIU en el ciclo enero-abril del año 2004.-
3. Las Variables
La variable es un símbolo (X,Y,Z) que puede tomar un conjunto prefijado de valores. Estos valores que toma una variable se llaman Dominio de la Variable.
Las variables pueden ser discretas y continuas.
Variable Discreta: es la variable que solamente toma un valor, es decir, que la unidad de medida no es divisible, solamente se expresa en término de la unidad entera. Una variable discreta viene definida de tal modo que tan solo puede alcanzar un determinado conjunto de valores, ya que la escala de medición se encuentra ininterrumpida por espacios en la escala numérica que, en un principio, no contiene casos medidos de ningún tipo. En este sentido, los ingresos o el tamaño de la población son variables discretas ya que los números o valores correspondientes varían a saltos o escalonadamente
Ejemplo: el número de hijos paridos por una mujer.
Se observa que como una mujer no puede parir 1 ½ hijos, no hay rompimiento de la escala de medición.
Variable Continua es aquella para la que los individuos pueden tener, en principio, infinitos valores fraccionados, esto es valores en cualquier punto de una escala ininterrumpida. Así la distancia o la edad serían variables continuas en el sentido de que entre cualquier par de mediciones o valores, por próximos que sean, es posible obtener otra medición o valor.
La diferencia entre variable discreta y variable continua se basa en el contenido formal de la escala de medición, que puede presentar una distribución discreta o continua.
Desarrollar una sumatoria simple no es más que darle a la variable índice los valores indicados desde ese índice hasta N. El símbolo de sumatoria representa la letra griega “Sigma” que corresponde a la letra mayúscula “S”, y se utiliza para indicar suma. Cuando se tienen “N” cantidades X1 + X2 + X3……….Xn, la suma de ellas, se puede abreviar de la siguiente forma:
n
La letra (i), es la variable que se considera índice de la Sumatoria y toma por valores solamente número naturales consecutivos entre 1 y n. Para obtener el número de términos en una sumatoria simple, se resta el límite superior menos el límite inferior de la sumatoria y se le suma (1). Ejemplo:
10
X²; No. De términos = (10-4)+1=6+1=7
X=4
Un conjunto de datos, ya sean procedentes de una población o de una muestra, después de recolectados, llegan al analista de datos de manera desordenadas, y que es labor del analista dar un ordenamiento a estos, de la forma que él como especialistas así lo considere.
No es más que la diferencia dada por el valor máximo menos el valor mínimo o sea:
R=v.ma – v.mi
R= 30-8
R=22
Para saber un número aproximado de clases, donde serán agrupados x cantidad de datos. La fórmula que utilizará será la de “Sturges”, o sea, C=1+3.3. log n. si son 60 datos, sería:
C= 1+3.3. log 60
C= 1+3.3. (1.778151)
C= 6.86 = Redondeado hasta 7 clases.
Se debe tener presente que al construir una distribución de clases y frecuencias, nunca deberá tener menos de 5 clases, ni más de 15 clases y además debe recordar que el cálculo hecho por la fórmula de Sturges es solo una aproximación de las clases que necesitará, o sea, que puede ser que los datos se agrupen enana o dos clases menos o más que el cálculo hecho.
5.2. Clases
Una clase es la conjugación de dos límites de clases, un llamado límite inferior y el otro llamado límite superior.
Siempre al construir una distribución de clases y frecuencias, el primer valor de la serie de datos o sea, el más pequeño, será su primer límite inferior. Luego a este primer límite se le suma el tamaño del intervalo y se obtienen el límite superior. Para que no se pierda ningún valor, debe considerar todo el tiempo los límites superiores como imaginarios, o sea, si su primera clase dice ocho (8) a menos de once (11), el límite inferior de su segunda clase debe empezar en (11), ya que ningún valor igual o mayor que once (11) cabe en la primera clase.
5.3. Frecuencias Simples (Fi)
Es la cantidad de valores que corresponden a una clase específica.
5.4. Frecuencias Acumuladas (Fa)
Es una suma acumulativa de las frecuencias simples, o sea, para nuestro ejemplo la primera frecuencia simple (10), es igual siempre a la primera frecuencia acumulada. La segunda frecuencia acumulada es igual a la primera frecuencia acumulada más la segunda frecuencia simple, o sea, (10+8=18), y así sucesivamente. Por último la frecuencia acumulada debe ser igual al tamaño de n, o sea, (60).
5.5. Frecuencias Relativas (Fr): esta surge cuando se divide de manera individual cada una de las frecuencias simples entre el total de frecuencias. Por ejemplo, su primera frecuencia simple es 10 dividido entre 60, le da su primera frecuencia relativa, 10/60=0.14
5.5. Los puntos medios o marcas de clases (Xi)
Estos surgen como una semisuma de un límite inferior más un límite superior dividido por (2), o sea, para la primera clase el punto medio es 8+11/2= 19/2=9.5. Los demás puntos medios se obtienen usando el mismo proceso.
Un gráfico es una forma de expresar el comportamiento de un conjunto de datos. El gráfico debe ser un instrumento claro, preciso y legible de forma, que el público más sencillo pueda leerlo y entenderlo.
Existen diferentes variedades de gráficos de acuerdo al tipo de datos que se quiera graficar como son:
- Histogramas de frecuencias
- Polígono de frecuencias
- Gráfico de de barras
- Gráfico lineal
- Gráfico del cien por ciento
- Gráfico de tela araña y otros
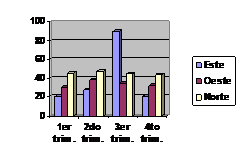
Un histograma consiste en una serie de rectángulos, cuyo ancho es proporcional al alcance de los datos que se encuentran dentro de una clase, y cuya altura es proporcional al número de elementos que caen dentro de cada clase. Si las clases que utilizamos en la distribución de frecuencias son del mismo ancho, entonces las barras verticales del histograma también tienen el mismo ancho. La altura de la barra correspondiente a cada clase representa el número de observaciones de la clase. Como consecuencia, el área contenida en cada rectángulo (ancho por altura) ocupa un porcentaje del área total de todos los rectángulos igual al porcentaje de la frecuencia de la clase correspondiente con respecto a todas las observaciones hechas.
Un histograma que utiliza las frecuencias relativas de los puntos de dato de cada una de las clases, en lugar de usar el número real de puntos, se conoce como histograma de frecuencias relativas. Este tipo de histograma tiene la misma forma que un histograma de frecuencias absolutas construido a partir del mismo conjunto de datos. Esto es así debido a que en ambos, el tamaño relativo de cada rectángulo es la frecuencia de esa clase comparada con el número total de observaciones.
6.1.1.1. Ventajas de los histogramas:
- Los rectángulos muestran cada clase de la distribución por separado.
- El área de cada rectángulo, en relación con el resto, muestra la proporción del número total de observaciones que se encuentran en esa clase.
6.1.2. Polígonos de frecuencias.
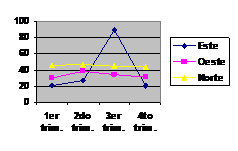
Son otra forma de representar gráficamente distribuciones tanto de frecuencias simples como relativas. Para construir un polígono de frecuencias señalamos éstas en el eje vertical y los valores de la variable que estamos midiendo en el eje horizontal. A continuación, graficamos cada frecuencia de clase trazando un punto sobre su punto medio y conectamos los resultantes puntos sucesivos con una línea recta para formar un polígono.
Se añaden dos clases, una en cada extremo de la escala de valores observados. Estas dos nuevas clases que contienen cero observaciones permiten que el polígono alcance el eje horizontal en ambos extremos de la distribución.
Un polígono de frecuencias es sólo una línea que conecta los puntos medios de todas las barras de un histograma. Por consiguiente, podemos reproducir el histograma mediante el trazado de líneas verticales desde los límites de clase y luego conectando tales líneas con rectas horizontales a la altura de los puntos medios del polígono.
Un polígono de frecuencias que utiliza frecuencias relativas de puntos de dato en cada una de las clases, en lugar del número real de puntos, se conoce como polígono de frecuencias relativas. Este polígono tiene la misma forma que el polígono de frecuencias construido a partir del mismo conjunto de datos, pero con una escala diferente en los valores del eje vertical.
6.1.2.1. Ventajas de los polígonos de frecuencias
- Es más sencillo que su correspondiente histograma.
- Traza con más claridad el perfil del patrón de datos.
- Se vuelve cada vez más liso y parecido a una curva conforme aumentamos el número de clases y el número de observaciones. Un polígono alisado mediante el aumento de clases y de puntos de dato se conoce como curva de frecuencias.
6.1.3. Propiedades del Histograma y el Polígono de Frecuencias
- Las frecuencias simples de clases, se grafican en el eje de ordenadas o eje (Y).
- Los intervalos de clases se representan en escala en el eje de abscisa o eje (X).
- El eje de ordenada o eje (Y), debe empezar en cero y no puede tener ningún tipo de ruptura.
- Un espacio de la mitad al tamaño completo del intervalo de clase se deja en cada extremo del eje de abscisa o eje (X).
- Las designaciones en la escala (X), se colocan generalmente en los límites de clases. Si los datos son continuos o se tratan como tales, el límite superior de una clase coincide con el límite inferior de la clase siguiente.
- Si los datos son discretos, la escala (X) solo se designa en términos de los límites inferiores de clase.
- La Proporción
Es un cociente que surge cuando se dividen unidades de datos originales con ciertos atributos, entre el total de unidades con y sin atributos.
P=X/N*100
P=proporción
X= unidades que poseen ciertos atributos
N= conjunto total de unidades
- Medidas de Tendencia Central
Estas medidas describen en forma de resumen una gran cantidad de datos cuantitativos. También estas medidas permiten la comparación entre dos o más conjuntos de datos del mismo tamaño. Las medidas de tendencia central, es lo que de manera popular la gente entiende como “promedio”. Reciben el nombre de promedio, porque expresa el centro de gravedad de un conjunto de datos, es decir, que los datos se distribuyen alrededor de un valor central.
Esta medida se define como el cociente a obtenerse cuando se divide la suma de los valores que asume una variable entre el total de valores X (se lee x barra), es el símbolo que identifica a la media aritmética.
X =X1+X2+X3+…Xn
n
8.1.1. Propiedades
- Es la medida de tendencia central más confiable y más usada dentro de estas.
- Es la medida básica para desarrollar el criterio de lo mínimos cuadrados.
- Las desviaciones que se tomen con relación a ella son iguales a cero.
- Es afectada por los valores extremos, es decir, si se tiene la serie x=1, 2, 300, este último valor afecta el resultado real de esta medida.
- La media aritmética es un valor típico, es el centro de gravedad de una serie de valores.
- Los valores de la serie se pueden sustituir por el valor de la media aritmética, sin que esta se altere.
8.1.2. La Media Aritmética para Datos Simples
X = X1/n (no están agrupados)
Ejemplo: Sea la serie X=1,4,5,7,8,10
X =35/6=5.83
8.1.3. La Media Aritmética para Datos Agrupados
Existen tres métodos para calcular la media aritmética en una serie de datos agrupados que son:
8.1.3.1. El método largo: X=Fi*Xi
n
Clases |
Fi |
Xi |
FiXi |
8 a menos de 11 |
10 |
9.5 |
95.0 |
11 a menos de 14 |
8 |
12.5 |
100.0 |
14 a menos de 17 |
11 |
15.5 |
170.5 |
17 a menos de 20 |
9 |
18.5 |
166.5 |
20 a menos de 23 |
10 |
21.5 |
215.0 |
23 a menos de 26 |
4 |
24.5 |
98.0 |
26 a menos de 29 |
1 |
27.5 |
27.5 |
29 a menos de 32 |
7 |
30.5 |
213.5 |
Total |
N=60 |
|
1086 |
X= 1086=18.10
60
La interpretación de este cálculo es que estos estudiantes promedian una edad en conjunto de 18 años y 1 mes.
8.1.3.2. El método Abreviado en Unidades Originales
X = Ms + (d´fi/n)
Este método parte de la propiedad que dice que las desviaciones con relación a la media son iguales a cero. Lo primero que debe hacerse es elegir una medida supuesta (Ms), que no sea la media aritmética. Esto es un punto cualquiera de los puntos medios o marcas de clases. Como ejemplo, se elige como MS el punto 21.5.
Las desviaciones con relación a la media supuesta, las obtendrá restando cada punto medio o marca de clases menos la media supuesta. Esto es, 9.5-21.5=-12.
Edades de una población de 60 personas
Clases |
Fi |
Xi |
FiXi |
d´=(Xi-Ms) |
d´fi |
8 a menos de 11 |
10 |
9.5 |
95.0 |
-12 |
-120 |
11 a menos de 14 |
8 |
12.5 |
100.0 |
19 |
-72 |
14 a menos de 17 |
11 |
12.5 |
170.5 |
16 |
-66 |
17 a menos de 20 |
9 |
18.5 |
166.5 |
13 |
-27 |
20 a menos de 23 |
10 |
21.5 |
215.0 |
0 |
0 |
23 a menos de 26 |
4 |
24.5 |
98.0 |
3 |
+12 |
26 a menos de 29 |
1 |
27.5 |
27.5 |
6 |
+6 |
29 a menos de 32 |
7 |
30.5 |
213.5 |
9 |
+63 |
Total |
N=60 |
|
|
|
|
-285
-204
+81
X=21.5+(-204/60)=21.5+(-3.4)=18.10
8.1.3.3. Método Abreviado por Intervalos de Clases
Este método se parece bastante al anterior, diferenciándose en que aquí se hace uso del intervalo de la distribución. Cuando la distribución esta formada, el intervalo de la misma se obtiene restando dos límites superiores sucesivos o dos límites inferiores sucesivos.
Ejemplo:
a) 23-20=3
b) 11-8= 3
X= Ms+(d´fi/n)i
Clases |
Fi |
Xi |
D´ |
d´fi |
8 - 11 |
10 |
9.5 |
-1 |
-10 |
11- 14 |
8 |
12.5 |
0 |
+0 |
14 - 17 |
11 |
12.5 |
+1 |
+11 |
17 - 20 |
9 |
18.5 |
+2 |
+18 |
20 - 23 |
10 |
21.5 |
+3 |
+30 |
23 - 26 |
4 |
24.5 |
+4 |
+16 |
26 - 29 |
1 |
27.5 |
+5 |
+5 |
29 - 32 |
7 |
30.5 |
+6 |
+42 |
Total |
N=60 |
|
|
|
Tenemos por ejemplo el punto medio 12.5, o sea (Ms9. Las desviaciones se obtendrán contando positivamente por debajo de la media supuesta y negativamente por encima. Luego multiplica las desviaciones por las frecuencias de clases, luego divide por el total de frecuencias (60) y lo que le dé lo multiplica por el intervalo de clases (3). Luego el resultado de este factor de corrección lo suma a la media supuesta elegida anteriormente, o sea, 12.5.
X =12.5+ (112/60)3
X =12.5+5.6 = 18.10
8.2. La Media Geométrica
La media geométrica se define como la raíz enésima del producto de “n” cantidades. Su símbolo ğ.
8.2.1. Propiedades
- Su cálculo se usa para promediar tasas de cambio.
- Se usa para calcular razones promedio.
- Se usa en el cálculo de datos que muestren una progresión feom♪0trica.
- Su resultado es siempre menor que el de la media aritmética.
- Se calcula para serie de datos distribuidos logarítmicamente.
- Su cálculo no tiene sentido para datos negativos.
8.2.2. La Media Geométrica Para Datos Simples
ğ = √(X1)(X2)(X3)…(Xn)
Ejemplo:
X= 1,2,3,4,5
ğ = (1)(2)(3)(4)(5)= √120
8.2.3. La Media Geométrica para Datos Agrupados
ğ =Ant. Log – fi*LogXi
n
Clases |
fi |
xi |
Log.x1 |
Fi.Log x1 |
8 a menos 11 |
10 |
9.5 |
0.9777 |
9.7770 |
11 a menos 14 |
8 |
12.5 |
1.0969 |
8.7752 |
14 a menos 17 |
11 |
15.5 |
1.1903 |
13.0933 |
17 a menos 20 |
9 |
18.5 |
1.2672 |
11.4048 |
20 a menos 23 |
10 |
21.5 |
1.3324 |
13.3240 |
23 a menos 27 |
4 |
24.5 |
1.3892 |
5.5568 |
27 a menos 30 |
1 |
27.5 |
1.4393 |
1.4393 |
30 a menos 32 |
7 |
30.5 |
1.4843 |
10.3901 |
Total |
N=60 |
|
|
73.7605 |
Este resultado se interpreta como que, los estudiantes promedian en edad 16 años y 11 meses. Se puede notar que este promedio es menos que el de la media aritmética y esto se debe en gran parte al redondeo de los datos.
8.2.4. Fórmulas de Proyecciones Geométricas o Decrecimiento Geométrico
En este tema se usarán 2 fórmulas, una que sirve para proyectar hacia el año 2n”, y la otra para calcular una tasa promedio de crecimiento.
Pn=Po(1+r)n
R=(Pn/Po)¹/n -1
Po = Tamaño de la población en el período o año base.
n= Número de períodos o años hacia donde queremos proyectar.
r= Tasa de crecimiento promedio.
Ejemplo: En un país A, la población al año 1980 era de 4,234,700 habitantes y para el año 1990 era de 7,125,540 habitantes.
Calcule una tasa de crecimiento promedio para el periodo 80-90. Proyecte la población al año 2000 usando la tasa calculada.
r=(7,125,540/4,234,700) 1/10 - 1=(1.682652) 0.1 – 1= 1.053415 -1= 0.0534= 5.34%
P2000= 7,125,540 (1+0.0534)10= 7,125,540 (1.0534)10= 7,125,540 (1.682415)= 11,988,115 habitantes.
Esta se define como el reciproco de la medida aritmética del recíproco de los valores que asume la variable.
- Es de gran utilidad en el cálculo de datos compuestos.
- Es buena indicadora para analizar problemas de velocidad.
- Es buena indicadora en problema de rendimiento.
- Cálculo de la Media Armónica para Datos No Agrupados
A= Media Armónica
A= N = A= N
1 + 1 + 1+……1 n
x1 x2 x3 xn 1
xi
i= 1
Ejemplo: X=1,2,3,4,5,6,
A= 6 Busque un común denominador, en este caso es 60.
1+1+1+1+1+1
1 2 3 4 5 6
A= 6 = 6 = 360 = 2.45
60+30+20+15+12+10 147 147
- Cálculo de la Media Armónica para Datos Agrupados
A= N
f1(1/x1) + (1/x2) + f3(1/x3) + ….fn(1/xn)
La diferencia con relación a la fórmula anterior es que está multiplicando los recíprocos por las frecuencias simples de clases.
Ejemplo: Muestra de 12 niños que practican artes marciales
Clases |
fi |
xi |
fi 1/x |
fi 1/x1 |
fi.1/x1 |
2 – 5 |
1 |
3.5 |
(1) (1/3.5) |
1/3.5 |
0.28 |
5 – 8 |
2 |
6.5 |
(2) (1/6.5) |
2/6.5 |
0.31 |
8 – 11 |
4 |
9.5 |
(4) (1/9.5) |
4/9.5 |
0.42 |
11 – 4 |
3 |
12.5 |
(3) (1/2.5) |
3/12.5 |
0.24 |
14 – 17 |
2 |
15.5 |
(2) (1/15.5) |
2/15.5 |
0.13 |
Total |
N=12 |
|
|
|
1.38 |
Fuente: Datos que provienen de la escuela B.
A= 12/1.38 = 8.69
Esta se define como la raíz cuadrada de la Media Aritmética de los cuadrados de los valores. La propiedad más importante de esta medida es que sirve como soporte en el cálculo de otras medidas como la varianza y la desviación estándar.
- La Media Cuadrática para Datos Agrupados
Xc = ∑fixi²
N
Clases |
fi |
xi |
xi² |
fi.x1² |
5 – 9 |
5 |
7 |
49 |
245 |
10 - 14 |
7 |
12 |
144 |
1008 |
15 - 19 |
9 |
17 |
289 |
2601 |
20 - 24 |
10 |
22 |
484 |
4840 |
25 - 29 |
6 |
27 |
729 |
4374 |
30 - 34 |
4 |
32 |
1024 |
4096 |
|
N=41 |
|
|
17164 |
Xc= 17164 = 418.63 = 20.46
41
- La Media Aritmética Ponderada
Es un promedio ponderado en donde cada uno de los valores se pondera de acuerdo con su importancia dentro de l conjunto de datos.
Xp = _ Wxi
W
x= Valores de la variable.
W= Factor de Ponderación.
Xp= Media aritmética Ponderada.
Es un buen indicador para calcular costos medios de producción.
Puede usarse para promediar números índices.
Puede usarse para promediar tasas de cambio.
Ejemplo:
En una firma de Gerencia, hay 10 gerentes que ganan RD$ 6,720 pesos semanal cada uno, 4 gerentes antiguos que reciben RD$ 9,520 pesos semanal cada uno y un especialista que reciben RD$ 14,000 pesos semanal. Calcule La Media Aritmética Ponderada para los salarios semanal de ese personal.
Xp= 6720*10) + (9520*4) + (14000*1) = 67200+38080+14000 = 119,280 = 7952
15 15 15
Es una medida de posición dentro del conjunto de medidas de tendencia central, esto así, porque se calcula localizando un valor en la serie de datos. La mediana se comporta de tal manera que divide la serie de datos en partes dos iguales, de tal manera que la mitad son mayores que ella y la otra mitad son menores que ella.
- Es influida o afectada por el número de valores que tenga la serie de datos.
- Su cálculo no tiene sentido para datos cualitativos.
- Se usa mucho su cálculo en distribuciones de frecuencias donde hallan clases abiertas.
- Las desviaciones absolutas que s realizan con ella son iguales a un mínimo.
- Es afectada por la posición de los valores en la serie de datos.
- Cálculo de la Mediana para Datos Simples
Me=Mediana
Se presentan dos casos:
- Que la serie de datos sea par.
Ejemplo: X=1,2,3,4,5,6,7,8.
Me= a la semisuma de los valores que dividen la serie en partes iguales o sea,
Me= 4+5=9=4.5
- Que la serie de datos sea impar.
Ejemplo: X=1,2,3,4,5.
Aquí la mediana se localiza de forma directa o sea, Me=3, es decir, el valor que divide la serie en dos partes iguales.
- Cálculo de la Mediana para Datos Agrupados
Fórmula
Me = Li + [(n/2 – Fa-i)/Fi]
Me =Mediana
Li =Límite inferior de la clase mediana
n/2 = Punto que sirve para localizar la clase mediana.
Fa – 1= Total de Frecuencias acumuladas antes de la clase mediana.
Fi= Frecuencia simple de la clase mediana
I= Intervalo de clase de la distribución.
Calculemos la mediana con estos datos: n/2= 30/2=15. Este punto o valor se ubica en la columna de frecuencias acumuladas. En algunos casos este punto es igual a un valor acumulado, en otro caso, usted elegirá el valor acumulado que excede al punto n/2. Como se puede observar de acuerdo al punto n/2=15 la clase mediana será (8-10), tomará de esta clase los datos que le interesan para completar la fórmula.
Clases |
Fi |
Fa |
2-4 |
2 |
2 |
4-6 |
3 |
2 |
6-8 |
5 |
10 |
8-10 |
8 |
18 |
10-12 |
6 |
24 |
12-14 |
4 |
28 |
14-16 |
2 |
30 |
Total |
N=30 |
|
Me= 8 + [(30/2 – 10)/8]2
Me= 8 + [(15-10)/8]2
Me= 8 + (5/8)2
Me= 8 + (0.625) 2
Me= 8+ 1.25 = 9.25
Es el valor que más se repite en una serie de datos. Al igual que la media aritmética y la median es un buen indicador para describir y resumir una serie de datos.
- En una serie de datos monomodal no agrupados, la moda será siempre un valor de la serie.
- En una serie discreta cualquier valor puede ser moda excepto que el número de apariciones no excede a otro valor adyacente.
- Es un valor hasta cierto punto inestable, pues cambia radicalmente si no se modifica el método de redondeo de datos.
- La Moda para Datos Simples
Mo = Moda
Ejemplo: X = 2, 3, 4, 5, 5, 6,7. (Pesos en libras de un grupo de niños que acaba de nacer). La moda es el 5, ya que es el valor que más se repite.
- La Moda para Datos Agrupados
Mo=Li+[Δ1/Δ1+Δ2]i
Li= Límite inferior de clase.
Δ1= Frecuencia simple premodal menos la frecuencia modal (no se toma en cuenta el signo).
Δ2= Frecuencia simple de la clase modal menos la frecuencia simple posmodal.
i= Intervalo de clase.
Clases |
Fi |
70-75 |
8 |
75-80 |
12 |
80-85 |
15 |
85-90 |
18 |
90-95 |
10 |
95-100 |
6 |
100-105 |
6 |
Total |
N=75 |
La clase modal se obtiene escogiendo aquella que tenga la frecuencia simple más alta.
Δ1=15-18, o sea, la frecuencia premodal menos la modal (sin tomar en cuenta los signos).
Δ2=(-3), o sea, 3.
Δ2=18-10, o sea, la frecuencia modal menos la posmodal, es decir, 18-10=8.
Mo= 85+ [(3)/ (3+8)]5 = 85+ (3/10)5= 86.36
Imaginando que estos datos muestran lo que gana cada uno de esos muchachos que están en los semáforos diariamente, se determina que ganan diariamente una cantidad que fluctúa entre los 85-90 pesos.
Estas medidas siguen un curso paralelo a de la mediana o sea, que mientras que la mediana divide la serie en dos partes iguales, los deciles en diez partes iguales, los cuarteles en cuatro partes iguales y los percentiles en cien partes iguales.
Dk= K(n+1) / 10
Dk= es el decil buscado
K= es el decil de orden que se elige arbitrariamente con una posición de la serie.
N= número de datos o valores que tenga la serie.
Ejemplo:
Los siguientes datos son las carreras promedio que hizo un equipo X durante 10 juegos. X=3, 5, 7, 7, 7, 8, 9, 9, 10,10. Si se calcula el decil de orden (6), tenemos:
D6=6(10+1) /10= 6(11)/10=66/10=6.6
Esta es la posición del decil buscado, en otras palabras, el decil 6 se encuentra en la posición 6.6, por lo tanto debe interpolar para encontrar el valor verdadero de D6 que representa las posiciones 6 y 7.
D6=8+0.6 (9-8)
D6=8.6 carreras promedio. Este cálculo nos indica que en el 60% de los juegos, el equipo X promedió 8.6 carreras o menos.
Qk=K(n+1) / 4
Qk=cuartil buscado
K=cuartil que específicamente se desea buscar.
Ejemplo:
Para la serie anterior X=3, 5, 7, 7, 7,8, 9, 9, 10, 10, calcule el cuartil No. 3.
Q3= 3(n+1) /4= 3(10+1) / 4 = 3(11)/4= 33/4=8.25. Este resultado nos indica que el cuartil No. 3 se encuentra en el lugar 8.25, por lo tanto debe interpolar para encontrar su verdadero valor.
Q3= 9+0.25 (10-9)
Q3=9.25 carreras promedio. Este resultado nos indica que en el 75% de los juegos, el equipo X promedia 9.25 carreras o menos.
Pk= K8n+1) / 100
Pk= Percentil buscado
Ejemplo:
Siguiendo con la misma serie anterior o sea, X=3, 5, 7, 7, 7, 8, 9, 9, 10,10, calcule P40.
P40=40(n+1) / 100 = 40(10+1) / 100= 40_(11) / 100= 440/100=4.4. Se sigue el mismo proceso de interpolación o sea:
P40= 4+0.4 (7-7)
P40= 4+0.4 (0)
P40= 4+0
P40= 4
Este resultado indica que en el 40% de los juegos, el equipo X promedia 4 carreras o menos.
- Cálculo de deciles, cuartiles y percentiles para datos agrupados
El procedimiento para el cálculo de estas medidas es prácticamente el mismo usado en la mediana. Las fórmulas son las siguientes:
Dk= Li + Kn - Fa -1
10_________ i
Fi
Qk= Li + Kn - Fa -1
4__________ i
Fi
Pk= Li + Kn - Fa -1
100_________ i
Fi
9. Medidas de Variabilidad y Dispersión
La variación es la esencia de la estadística. Los datos cuantitativos, materia prima para el análisis estadístico, se caracterizan siempre por diferenciarse uno del otro. De ahí que decimos que la estadística es la ciencia de los promedios, podemos decir también que todos los métodos estadísticos son técnicas para estudiar la variación.
9.1. La Fluctuación
A esta medida suele llamársele también rango y es la diferencia dad por el valor máximo menos el valor mínimo si los datos presentados son simples.
Ejemplo: Sea la serie X=2-3-5-6-8-10
F=Fluctuación
F=10-2=8
Si los datos presentados son o están agrupados, la fluctuación se halla restando el límite de clase superior de la última clase menos el límite de clase inferior de la primera clase. Ejemplo:
Clases
15-19 F=44-15=29
- -
40-44
9.1.1. Propiedades
- Puede estar indebidamente incluida por un valor no usual en el conjunto de datos.
- Es altamente sensible al tamaño de la muestra.
9.1.2.
No es más que la diferencia entre cuartiles de mayor a menor. Por ejemplo la diferencia de Q3 y Q1. Suponemos que Q3=1014.28, y Q1)=720. Entonces,
Fi=Q3-Q1= 1014.28-720=294.28
9.1.3.
Conclusión
La estadística es una ciencia con un amplio campo de acción. Mediante esta, se recolecta, se ordena, se resume, y se interpretan datos, obtenidos utilizando ciertas técnicas, como lo es la encuesta.
Es utilizada a partir de la formación de las sociedades humanas, hasta en al Biblia, se menciona un censo, que no es más que un estudio o un conteo donde se determinan la cantidad de habitantes de un país.
La estadística se divide en dos grandes ramas, y de estas se subdividen otras. Estas son la descriptiva y la inferencial. La primera solo se ocupa de describir y analizar un conjunto determinando de datos.; y la segunda permite inferir a la población, o conjunto de valores cuantificables, observando una parte representativa de ella.
Para el resumen y distribución se usan un sin número de índices y fórmulas. Se representan estas distribuciones en gráficos de frecuencias, en donde el más utilizado es el histograma y el polígono de frecuencias. Existen ciertas similitudes en ambos, pero se diferencian en que el histograma se representa mediante rectángulos que representan las frecuencias de clases, y en el polígono de frecuencia se unen los puntos medios de las frecuencias de clases, con una línea.
En adicción, se cuenta con una gran variedad de medidas centrales, de simetría, de variabilidad, dispersión, índices compuestos, etc., cuyo uso dependerá del estudio de que se trate. Son de gran utilidad, especialmente en el área económica, ya que permiten determinar la variación de determinados datos, en un periodo determinado y así corregir errores en un presente. Algunas de estas medidas se pueden considerar como indicadores económicas, por su función en el desempeño de la economía.
Opinión Personal
Los conceptos antes mencionados han sido analizados e investigados de tal manera de hacer más fácil su comprensión y entendimientos ya que la estadística es la ciencia que trata de entender, organizar y tomar decisiones que estén de acuerdo con los análisis efectuados.
En nuestros días, la estadística se ha convertido en un método efectivo para describir con exactitud los valores de los datos económicos, políticos, sociales, psicológicos, biológicos y físicos, y sirve como herramienta para relacionar y analizar dichos datos. El trabajo del experto estadístico no consiste ya sólo en reunir y tabular los datos, sino sobre todo el proceso de interpretación de esa información. El desarrollo de la teoría de la probabilidad ha aumentado el alcance de las aplicaciones de la estadística. Muchos conjuntos de datos se pueden aproximar, con gran exactitud, utilizando determinadas distribuciones probabilísticas; los resultados de éstas se pueden utilizar para analizar datos estadísticos. La probabilidad es útil para comprobar la fiabilidad de las inferencias estadísticas y para predecir el tipo y la cantidad de datos necesarios en un determinado estudio estadístico.
La estadística es un potente auxiliar de muchas ciencias y actividades humanas: sociología, psicología, geografía humana, economía, etc.
Es una herramienta indispensable para la toma de decisiones.
También es ampliamente empleada para mostrar los aspectos cuantitativos de una situación.
La estadística está relacionada con el estudio de proceso cuyo resultado es más o menos imprescindible y con la finalidad de obtener conclusiones para tomar decisiones razonables de acuerdo con tales observaciones.
Bibliografía
- Pérez P., Víctor F. Manual básico de Estadística Descriptiva. 2000.
- Sarramona, Jaime. Estadística Aplicada a la Administración
- Spiegel, Murria. Estadística Aplicada. 2da Edición.
- Stevenson, William J. Estadística para Administración y Economía.


